Future of Design: Artificial intelligence for when times are a-changin’

In this Future of Design iteration, Maria Mingallon explains how we can utilise the data we have about our building decisions to make predictions using machine learning.
The third in our Future of Design series – which looks at how new and changing technologies are affecting the architecture, engineering and construction (AEC) industries – sees Maria Mingallon explore what artificial intelligence and machine learning are and what some of the potential benefits may be for the future.
Like electricity or the internet, artificial intelligence (AI) is considered a general purpose technology with the potential to transform productivity, accelerate economic growth and improve wellbeing across the whole of society. It has started, and will continue to, drastically transform the way we work and live. At least, this is what the report ‘Towards Our Intelligent Future’ published by New Zealand AI Forum earlier this year affirms. The report represents over nine months of collaborative work on parallel streams exploring AI adoption, policy and strategy in New Zealand and around the world. It highlights the value of AI for achieving New Zealand’s wellbeing, sustainability and economic goals.
If AI is so great and can do so much for humanity, why does it also provoke such strong reactions against it? Science-fiction thrillers have probably not contributed to promoting the good intentions behind AI. Thinking of Arnold Schwarzenegger in Terminator as a cyborg assassin fighting against AI dominance is an almost inevitable reaction for most of us. After all, who is interested in making a movie about the number of times we benefit from the use of AI-based algorithms when discovering a new song we like?
Ok, let’s give Hollywood a chance. Do you remember the movie Moneyball? It starred Brad Pitt in the role of Billy Bean who follows the advice of Peter Brand, a young Yale-educated research geek, with a degree in economics who is capable of crunching numbers to come up with suggestions about finding true baseball stars, based purely on data analytics and statistics.
While that is not (yet) AI, the movie does a great job of illustrating the benefits of data analytics, which are the foundation of any AI application. It also demonstrates how toxic our own bias can be, particularly inside boardrooms. Intrigued? This Forbes article expands on why business leaders need to take a proactive approach towards data analytics.
Despite its potential and wide usage, AI suffers from being a ‘suitcase term’ used to refer to everything from complex statistical algorithms to autonomous robots. The difficulty in describing AI succinctly might be one of the reasons why people react poorly to it. They simply don’t understand it. Almost all definitions I have come across include unnecessary verbiage which only contributes to mystifying a technology which, if conveniently democratised, has the potential to help resolve the many crises our planet suffers from.
We humans fear and criticise what we can’t understand. Nobel Laureate, Bob Dylan, referred to it in his lyrics of ‘The Times are A-Changin’. As Tuvok from Star Trek puts it, knowledge is a great strategy to overcome the fear that comes with novelty. On top of this, education is frequently identified as a barrier to the expansion of almost any new technology. In 2018, AI Forum of New Zealand reported that 44 per cent of survey respondents identified (lack of) education as a key barrier to AI adoption. Kaggle’s 2017 data in Figure 1 below also reports that “lack of data science talent” is the second largest barrier faced at work by data scientists.
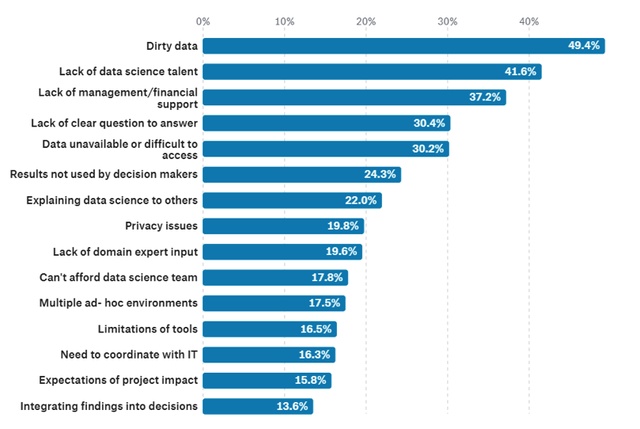
Figure 1: Barriers faced at work by data scientists. Lack of data science talent is the second greatest barrier. Source: Kaggle
Besides AI practitioners, leaders who understand the business context and potential of AI will have a clear competitive advantage. As a McKinsey puts it in their AI guide for executives: “It’s no longer the preserve of artificial-intelligence researchers and born-digital companies like Amazon, Google, and Netflix.” AI is a technology which can and will help anyone who understands how to best make use of it.
What is Artificial Intelligence?
Without using unnecessary technical language, AI is a technology which aims to replicate how a human brain thinks. In essence, it seeks to replicate how we perceive the world, extract data, analyze it and make decisions based on such data. It is all about how our brains create patterns that merge and join data to construct a version of the world within which we make decisions to take one direction or another.
So, data and data analytics are at the core of any AI application. That is actually the key difference between AI and traditional computing consisting of explicit programming instructions, such as ‘do’ something, ‘if’ a condition is ‘True’. Artificial Intelligence algorithms are fuelled on data. Between raw data and making intelligent informed decisions, there is first training and then learning. That is where machine learning comes in. Machine learning (ML) is a subset of AI which uses statistical analysis and algorithms to extract insights from large volumes of data. ML is essentially acquiring knowledge based on what has happened in the past.

Figure 2: Machine learning versus artificial intelligence. Source: Mott MacDonald
Think for a moment about how you first learned about the world. When you were a kid, your parents repeated the words ‘daddy’ and ‘mummy’ to you. They did it again and again and again, with slightly different variations such as wearing different clothes, being at the dinner table or while playing with you. They passed on their ‘image’ and the word associated with such image to you until you started pronouncing something that was a ‘good guess’ of what they were actually saying to you. They then smiled and reinforced your behaviour. They were ‘training’ you.
Training of a machine learning model happens in a similar way. Let’s call our ML experiment the ‘family member detection algorithm’. Each data point represents an instance when a family member met you and introduced themselves as ‘mummy’, ‘daddy’, ‘grandad’ and so on. Each time they might have worn different clothes, been in a different location, et cetera. By exposure to these different settings (features) you started recognising what remained constant: the facial traits of the family member in question and their associated position in the family. At some point in your infancy, you were able to recognise your mum and dad and, most importantly, distinguish them from a stranger.
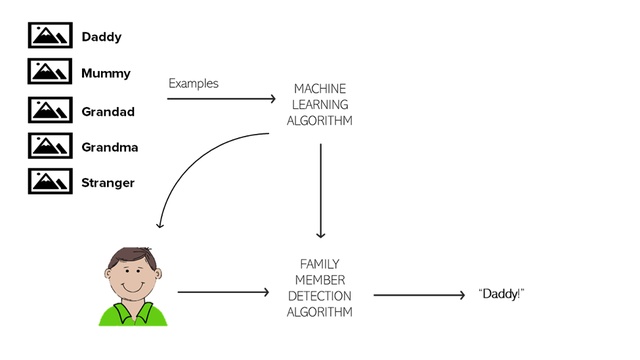
Figure 3: Diagram illustrating how a family member detection algorithm would work based on image recognition. Source: Mott MacDonald
Making predictions
Let me give you another example. Imagine that you would like to buy a home (hopefully not in Auckland where it is pretty difficult to afford anything reasonable). You know that the price of a property is normally directly proportional to the floor area. If you plot those two features you would most likely be able to visualise a ‘trend’, such as the one in Figure 4 below. You could in essence draw a straight line – a linear regression prediction – which, for a given floor area, would give you an idea of the price to expect. You could also choose to plot the points with a different colour based on the number of rooms.
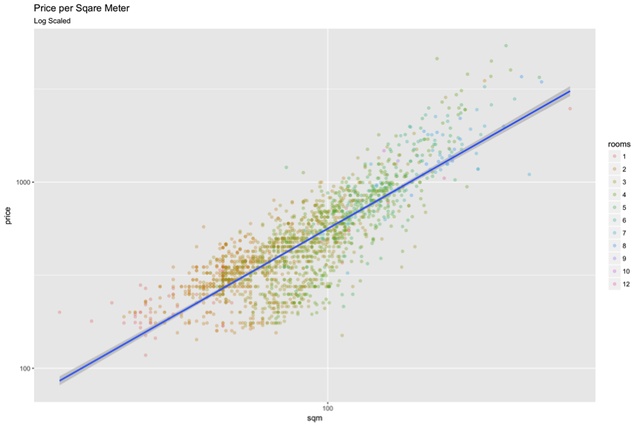
Figure 4: Scatter plot illustrating the relationship between the area of a dwelling, the number of rooms and the average house price. Source: Mike O’Connor on Medium
Of course, it is not so simple. There are many other factors that come into play such as number of bathrooms, parking spaces, garden area, neighbourhood, walkability index and perhaps even whether it has a fireplace. These are all ‘features’ of a data set in machine learning terms. Now, instead of plotting just two features as we did above, imagine you plot them all, using a correlation matrix. Have a look at Figures 5 and 6 to visualise the inner relationships between the typical features affecting the price of a house. The ones which are closer to 1.0 indicate a larger impact on the sale price.
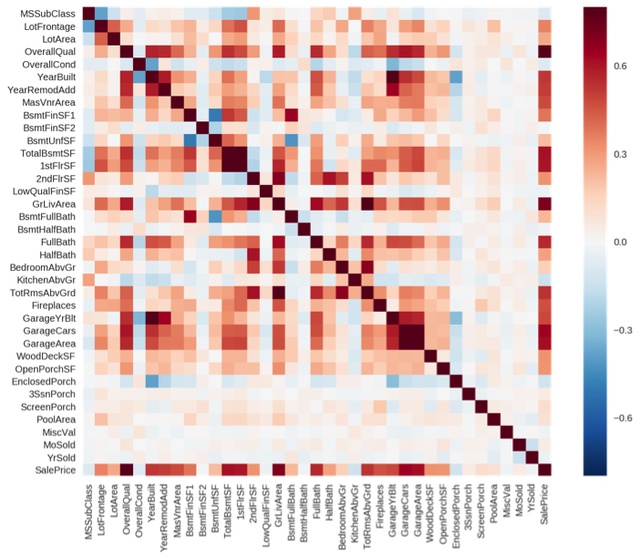
Figure 5: Correlation matrix of all features in housing data set. Source: Kaggle
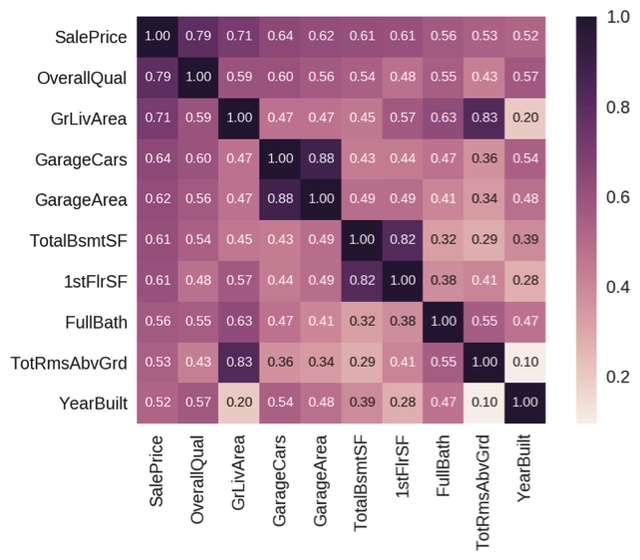
Figure 6: Zoomed in version of figure above, showing only the features with the highest impact on the sale price. Source: Kaggle
Once you have a decent understanding of your dataset, you can start training your model. How do you do that? You basically slice the dataset into two: the test and the training set. There are a number of papers on the subject of how many data entries should go to each set, but a good rule of thumb is 70 per cent for testing, the rest for training. As you may have guessed, the larger and the more accurate your dataset is, the easier it is to train your ML model and the higher the certainty of the predictions it would be able to make. The process of training the model is, in essence, passing on the data entries from the test set and comparing it to the training set, so that when a new entry comes in, it can make an informed guess: a prediction. That is what machine learning is in simple terms.
Hopefully you are still reading because the best part is yet to come. If you’re not a data scientist or a computer programmer, rest assured that almighty Bill Gates still has you in his thoughts! Microsoft Azure has recently launched a tool capable of undertaking machine learning on the cloud without any coding required. They recommend (or even choose for you) the ML algorithm best suited for your needs alongside the cloud computing processing power you would require to execute it.
All you need is to provide your datasets and of course, a clear formulation of what you are trying to predict from your data. A great tutorial from ‘Towards Data Science’ – a blog I recommend you start following – in case you are interested in giving it a go is available here.
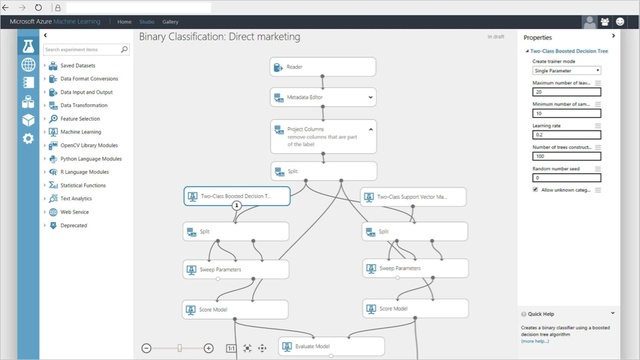
Figure 7: Microsoft Azure ML Studio offers visual scripting to minimise coding skills required to train machine learning models and obtain predictions. Source: Towards Data Science
Thus, we always come back to the data. Think about the data you have produced today. If you are a designer working in the AEC industry, it is quite likely that you have made decisions as to where to position a grid line, a window, a door, a pipe and what size they needed to be, et cetera. How are those decisions documented? You probably have it in front of you.
Your building information models (BIMs) are much more than mere representations of objects in the three dimensional space. They hold all of your design decisions. For example, the ratio between the location of a window and the overall dimensions of a room might come from past experience or perhaps the results of a sophisticated daylight simulation. Either way, the ratio between those elements is data your BIM hosts.
If you use BIM to document your projects, you are effectively in possession of a data mine, which is still hidden for most. What’s even better, think of all of those other projects you have done this year using BIM. If you were to put them all together, side by side, you would certainly be able to identify patterns, in particular if they are from the same sector (e.g. schools, hospitals). If you used BIM for all of them, chances are you can aggregate them to build your own dataset for training a machine learning algorithm which, next time, can help you predict where a window or a pipe should go and how big they need to be to be code compliant without necessarily running a single simulation.
Okay, that might sound like too big of a dream for now, but one thing is certain and that is the importance of curating your data. Refer to Figure 1 if you need proof. The results of the survey undertaken last year by AI Forum of New Zealand identified ‘dirty data’ as the highest barrier to AI adoption[1]. So showing a little love for those models which host your data assets will certainly pay off in the future. How well you curate your data today matters more than ever before.
Hungry for more? I shall come back to you in the new year with examples of AI in the AEC industry. Until then, I leave you one last resource which will help you in your personal quest to conquer the heart of machine learning: a starting point from the aforementioned Towards Data Science. As the proverb goes in Spanish, “nunca es tarde si la dicha es buena”. Funnily enough, Google Translate AI algorithms have not (yet) been able to grasp a decent translation of such proverb.
Catch up on the others in the Future of Design series here.